動機
脱出・再入ループ、脱出・再入再帰計算、そして協調的マルチタスクは、問題を単一の制御フローを用いるよりも簡潔かつ優雅に解決する助けになります。このような広い範囲の実行制御動作をサポートするために使えるのが、コルーチン型のcoroutine<>です。
イベント駆動モデル
イベント駆動モデルとは、プログラムのフローをイベントにより定めるプログラミングパラダイムです。イベントは複数の独立したソースが生成し、すべての外側のソースを世話する1つのイベントディスパッチャが、イベントを検出するたびにコールバック関数(イベントハンドラー)をトリガーします(イベントループ)。アプリケーションはイベント選択(検出)とイベントハンドリングの2つに分割されます。
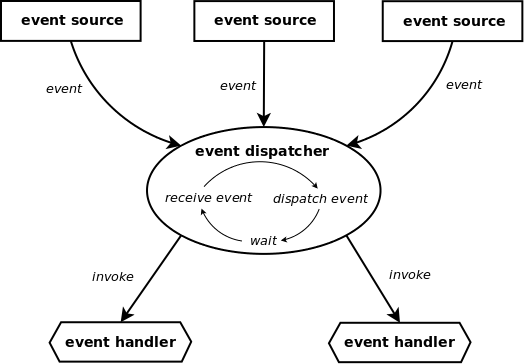
これで出来上がったアプリケーションは、高度にスケーラブルで、柔軟で、高い応答性を持ち、そしてコンポーネントの結合が疎になります。これによりイベント駆動モデルは、ユーザーインターフェースアプリケーション、ルールベースの制作システム、あるいは非同期I/Oを扱うアプリケーション(例えばネットワーク・サーバー)に向いています。
イベントベースの非同期パラダイム
古典的な同期コンソールプログラムはI/Oリクエスト(例:ユーザー入力やファイルシステムデータ)が問題となります。リクエストが完了するまでブロックしてしまうからです。
対して、非同期I/O関数は物理的な命令を開始しますが、しかし命令がまだ終わっていなくても、即座に呼び出し元にリターンします。プログラムを書くとき、この関数がブロックしないことを活用できます。つまり、元の命令がまだ保留されていても、他の作業へと進むことができるのです。命令が完了した時に、プログラムに知らせます。非同期アプリケーションは命令待ちの総時間が短いので、同期プログラムを凌ぐ性能を発揮できるのです。
イベントは非同期実行のパラダイムの1つです。すべての非同期システムがイベントを使っているわけではありません。非同期プログラミングはスレッドを使っても成し遂げられます。しかし、スレッドには特有のコストがあります:
- プログラミングが難しい(不用意に罠にかかる)
- メモリ要求が大きい
- 作成と状態の管理に大きなオーバーヘッドがある
- スレッド間のコンテキストスイッチが高価
イベントベースの非同期モデルはそういった問題を回避します:
- 命令ストリームが単一なのでより単純
- コンテキストスイッチが遥かに安価
このパラダイムの欠点は、プログラム構造が最善でないことによるものです。イベント駆動プログラムはコードを複数の小さなコールバック関数に分割することを要求します。すなわち、コードが断続的に実行される小さなステップの連なりとして構成されます。アルゴリズムは普通、関数の構造やループで表現されますが、これを複数のコールバックへと変形する必要があるのです。制御フローがイベントループへとリターンしても、完全な状態がデータ構造に保存されていなければなりません。結果として、イベント駆動アプリケーションを書くのは、しばしば退屈で紛らわしいことになってしまいます。各コールバックが新しいスコープとエラーコールバックを作るなどします。アルゴリズムの逐次的な性質が複数のコールスタックへと分割されて、アプリケーションのデバッグが難しくなります。例外ハンドラーはローカルハンドラーに限られてしまい、イベントの連なりを1つのtry-catchブロックで囲むことが不可能です。ローカル変数、while/forループ、再帰などをイベントループとともに使うことは出来ません。コードの表現力は乏しくなりました。
その昔、asioの非同期命令を使ったコードはコールバック関数で入り組んでいました。
class session
{
public:
session(boost::asio::io_service& io_service) :
socket_(io_service) // io_serviceからTCPソケットを作成
{}
tcp::socket& socket(){
return socket_;
}
void start(){
// 非同期読み込みを開始(handle_read() はコールバック関数)
socket_.async_read_some(boost::asio::buffer(data_,max_length),
boost::bind(&session::handle_read,this,
boost::asio::placeholders::error,
boost::asio::placeholders::bytes_transferred));
}
private:
void handle_read(const boost::system::error_code& error,
size_t bytes_transferred){
if (!error)
// 非同期書き込みを開始(handle_write() はコールバック関数)
boost::asio::async_write(socket_,
boost::asio::buffer(data_,bytes_transferred),
boost::bind(&session::handle_write,this,
boost::asio::placeholders::error));
else
delete this;
}
void handle_write(const boost::system::error_code& error){
if (!error)
// 非同期読み込みを開始(handle_read() はコールバック関数)
socket_.async_read_some(boost::asio::buffer(data_,max_length),
boost::bind(&session::handle_read,this,
boost::asio::placeholders::error,
boost::asio::placeholders::bytes_transferred));
else
delete this;
}
boost::asio::ip::tcp::socket socket_;
enum { max_length=1024 };
char data_[max_length];
};
この例では、シンプルなechoサーバーのロジックが3つのメンバ関数に分割されています。また、ローカル状態(データバッファーとか)はメンバ変数に移されています。
Boost.Asioは、新機能「非同期結果」を提供しています。これは、イベント駆動モデルとコルーチンを組み合わせた新たなフレームワークで、イベント駆動プログラミングの複雑さを隠し、古典的な逐次的なコードスタイルで書くことができるようにします。アプリケーションがコールバック関数を非同期命令に渡す必要はなく、ローカル状態はローカル変数として維持されます。したがって、コードがより読みやすく、理解しやすくなります。4
void session(boost::asio::io_service& io_service){
// io_serviceからTCPソケットを作成
boost::asio::ip::tcp::socket socket(io_service);
try{
for(;;){
// ローカルデータバッファー
char data[max_length];
boost::system::error_code ec;
// 非同期でデータをソケットから読み込む
// 実行コンテキストは数バイトがソケットから
// 読み込まれるまで停止される
std::size_t length=socket.async_read_some(
boost::asio::buffer(data),
boost::asio::yield[ec]);
if (ec==boost::asio::error::eof)
break; //ピアから接続がきちんと閉じられた
else if(ec)
throw boost::system::system_error(ec); //何かほかのエラー
// 非同期で数バイト書き込む
boost::asio::async_write(
socket,
boost::asio::buffer(data,length),
boost::asio::yield[ec]);
if (ec==boost::asio::error::eof)
break; //ピアから接続がきちんと閉じられた
else if(ec)
throw boost::system::system_error(ec); //何かほかのエラー
}
} catch(std::exception const& e){
std::cerr<<"Exception: "<<e.what()<<"\n";
}
}
非同期命令を使っているにもかかわらず、前の例に対して、逐次的なコードのような印象であり、ローカルデータ(data)がローカル変数です。アルゴリズムが1つの関数で実装され、エラーハンドリングが1つのtry-catchブロックで済んでいます。
再帰下降構文解析
コルーチンを使うと制御フローを逆転して、再帰下降構文解析器から、構文解析したシンボルを得ることができます。
class Parser{
char next;
std::istream& is;
std::function<void(char)> cb;
char pull(){
return std::char_traits<char>::to_char_type(is.get());
}
void scan(){
do{
next=pull();
}
while(isspace(next));
}
public:
Parser(std::istream& is_,std::function<void(char)> cb_) :
next(), is(is_), cb(cb_)
{}
void run() {
scan();
E();
}
private:
void E(){
T();
while (next=='+'||next=='-'){
cb(next);
scan();
T();
}
}
void T(){
S();
while (next=='*'||next=='/'){
cb(next);
scan();
S();
}
}
void S(){
if (std::isdigit(next)){
cb(next);
scan();
}
else if(next=='('){
cb(next);
scan();
E();
if (next==')'){
cb(next);
scan();
}else{
throw parser_error();
}
}
else{
throw parser_error();
}
}
};
typedef boost::coroutines2::coroutine< char > coro_t;
int main() {
std::istringstream is("1+1");
// 制御フローを逆転
coro_t::pull_type seq(
boost::coroutines2::fixedsize_stack(),
[&is](coro_t::push_type & yield) {
// 構文解析器をコールバック関数を設定して作成
Parser p( is,
[&yield](char ch){
// ユーザーコードを再開
yield(ch);
});
// 再帰構文解析を開始
p.run();
});
// ユーザーコードが構文解析したデータを構文解析器から引き出す
// 制御フローを逆転
for(char c:seq){
printf("Parsed: %c\n",c);
}
}
この問題は、独立したスレッド間で通信しようとすると、全くうまく行きません。各々の側で他と独立して進行させても無意味です。各々があちこちに制御を渡すようにしたいはずです。
他にもまだコルーチンを使う利点があります。この再帰下降構文解析器は構文解析に失敗した時に例外を投げます。コルーチンによる実装では、呼び出しコードをtry/catchで囲むだけで良いのです。
スレッド間通信で例外を掴むには、他のイベントを受け取るのに使っているキューに例外ポインターを渡すという工夫が必要になります。そのとき、再帰文書処理を巻き戻すため、例外を再スローする必要があるでしょう。
コルーチンによる解は、この問題の領域で非常にうまくいきます。
「同じフリンジ」問題
任意の呼び出し深度で停止できることの利点は、木をトラバーサルするときのような再帰関数を使った時に特に明らかになります。同じ決定論的順序の2つの異なる木があるとき、もしそれらをトラバーサルして同じ葉ノードのリストを得られたなら、2つの木は同じフリンジを持つと言います。
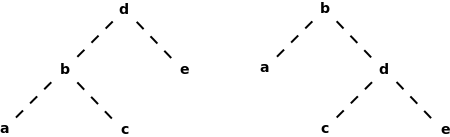
図の2つの木は構造が異なりますが、同じフリンジを持っています。
同じフリンジ問題は、コルーチンを使って葉ノードをイテレートしてstd::equal()で比較することで解けます。データ値のレンジは、関数traverse()が木をトラバーサルして各ノードのデータ値をcoroutine<>::push_typeに渡すことにより生成されます。coroutine<>::push_typeは再帰計算を停止して、データ値をメインの実行コンテキストに運びます。coroutine<>::pull_typeが作成するcoroutine<>::pull_type::iteratorは、データ値を順々にstd::equal()に届けて比較します。coroutine<>::pull_type::iteratorがインクリメントされるたびに、traverse()が再開されます。iterator::operator++()がリターンしたら、新しいデータ値が利用可能になるか、木のトラバーサルが完了(イテレーターが無効化されます)したかのどちらかです。
要するに、コルーチンイテレーターは、再帰データ構造の平坦化されたビューを提供するということです。
struct node{
typedef std::shared_ptr<node> ptr_t;
// それぞれの木のノードは左側と右側に部分木を
// 持つかもしれません。そして自身の値を持ちます。
// 値は左側と右側の木の間にあると仮定します。
ptr_t left,right;
std::string value;
// 葉ノードを作成
node(const std::string& v):
left(),right(),value(v)
{}
// 葉ではないノードを作成
node(ptr_t l,const std::string& v,ptr_t r):
left(l),right(r),value(v)
{}
static ptr_t create(const std::string& v){
return ptr_t(new node(v));
}
static ptr_t create(ptr_t l,const std::string& v,ptr_t r){
return ptr_t(new node(l,v,r));
}
};
node::ptr_t create_left_tree_from(const std::string& root){
/* --------
root
/ \
b e
/ \
a c
-------- */
return node::create(
node::create(
node::create("a"),
"b",
node::create("c")),
root,
node::create("e"));
}
node::ptr_t create_right_tree_from(const std::string& root){
/* --------
root
/ \
a d
/ \
c e
-------- */
return node::create(
node::create("a"),
root,
node::create(
node::create("c"),
"d",
node::create("e")));
}
typedef boost::coroutines2::coroutine<std::string> coro_t;
// 再帰的に木をたどり、順番に値を届ける
void traverse(node::ptr_t n,
coro_t::push_type& out){
if(n->left) traverse(n->left,out);
out(n->value);
if(n->right) traverse(n->right,out);
}
// 評価
{
node::ptr_t left_d(create_left_tree_from("d"));
coro_t::pull_type left_d_reader([&](coro_t::push_type & out){
traverse(left_d,out);
});
node::ptr_t right_b(create_right_tree_from("b"));
coro_t::pull_type right_b_reader([&](coro_t::push_type & out){
traverse(right_b,out);
});
std::cout << "left tree from d == right tree from b? "
<< std::boolalpha
<< std::equal(begin(left_d_reader),
end(left_d_reader),
begin(right_b_reader))
<< std::endl;
}
{
node::ptr_t left_d(create_left_tree_from("d"));
coro_t::pull_type left_d_reader([&](coro_t::push_type & out){
traverse(left_d,out);
});
node::ptr_t right_x(create_right_tree_from("x"));
coro_t::pull_type right_x_reader([&](coro_t::push_type & out){
traverse(right_x,out);
});
std::cout << "left tree from d == right tree from x? "
<< std::boolalpha
<< std::equal(begin(left_d_reader),
end(left_d_reader),
begin(right_x_reader))
<< std::endl;
}
std::cout << "Done" << std::endl;
output:
left tree from d == right tree from b? true
left tree from d == right tree from x? false
Done
コルーチンの連鎖
以下のコードは、どのようにしてコルーチンが連鎖されるかを示したものです。
typedef boost::coroutines2::coroutine<std::string> coro_t;
// 入力ストリームの各行を別々の文字列としてsinkへと届ける
void readlines(coro_t::push_type& sink,std::istream& in){
std::string line;
while(std::getline(in,line))
sink(line);
}
void tokenize(coro_t::push_type& sink, coro_t::pull_type& source){
// このトークナイザーはステートフルになりません。つまり新たなトークンを
// 下流へ押し入れるという挙動を、一度の呼び出しで手頃に実装できます。
// 私はステートフルトークナイザーを使ったことがありますが、そこでは
// 入力文字の意味は、入力行のどこにそれらがあるかに依存します。
for(std::string line:source){
std::string::size_type pos=0;
while(pos<line.length()){
if(line[pos]=='"'){
std::string token;
++pos; // 開始引用符をスキップ
while(pos<line.length()&&line[pos]!='"')
token+=line[pos++];
++pos; // 終了引用符をスキップ
sink(token); // トークンを下流へ押し入れる
} else if (std::isspace(line[pos])){
++pos; // 引用符の外側では、空白を無視
} else if (std::isalpha(line[pos])){
std::string token;
while (pos < line.length() && std::isalpha(line[pos]))
token += line[pos++];
sink(token); // トークンを下流へ押し入れる
} else { // 句読点
sink(std::string(1,line[pos++]));
}
}
}
}
void only_words(coro_t::push_type& sink,coro_t::pull_type& source){
for(std::string token:source){
if (!token.empty() && std::isalpha(token[0]))
sink(token);
}
}
void trace(coro_t::push_type& sink, coro_t::pull_type& source){
for(std::string token:source){
std::cout << "trace: '" << token << "'\n";
sink(token);
}
}
struct FinalEOL{
~FinalEOL(){
std::cout << std::endl;
}
};
void layout(coro_t::pull_type& source,int num,int width){
// 何が起きたとしても、最終行を終了する
FinalEOL eol;
// 上流から値を引き出して、num個を一行に展開する
for (;;){
for (int i = 0; i < num; ++i){
// 入力を使い果たしたらやめる
if (!source) return;
std::cout << std::setw(width) << source.get();
// この要素をハンドルし終わったので、次へ進む
source();
}
// num個の要素の後、改行する
std::cout << std::endl;
}
}
// 今回は例なので、ローカルファイルシステムの別個のテキストファイル
// でなく、istringstreamを作ってそこから読み込みます。
std::string data(
"This is the first line.\n"
"This, the second.\n"
"The third has \"a phrase\"!\n"
);
{
std::cout << "\nfilter:\n";
std::istringstream infile(data);
coro_t::pull_type reader(std::bind(readlines, _1, std::ref(infile)));
coro_t::pull_type tokenizer(std::bind(tokenize, _1, std::ref(reader)));
coro_t::pull_type filter(std::bind(only_words, _1, std::ref(tokenizer)));
coro_t::pull_type tracer(std::bind(trace, _1, std::ref(filter)));
for(std::string token:tracer){
// もうtracerから引き出したので、ただイテレートする
}
}
{
std::cout << "\nlayout() as coroutine::push_type:\n";
std::istringstream infile(data);
coro_t::pull_type reader(std::bind(readlines, _1, std::ref(infile)));
coro_t::pull_type tokenizer(std::bind(tokenize, _1, std::ref(reader)));
coro_t::pull_type filter(std::bind(only_words, _1, std::ref(tokenizer)));
coro_t::push_type writer(std::bind(layout, _1, 5, 15));
for(std::string token:filter){
writer(token);
}
}
{
std::cout << "\nfiltering output:\n";
std::istringstream infile(data);
coro_t::pull_type reader(std::bind(readlines,_1,std::ref(infile)));
coro_t::pull_type tokenizer(std::bind(tokenize,_1,std::ref(reader)));
coro_t::push_type writer(std::bind(layout,_1,5,15));
// APIの対称性により、push_typeコルーチンの連鎖でも
// どの連鎖する関数も使うことが出来ます。
coro_t::push_type filter(std::bind(only_words,std::ref(writer),_1));
for(std::string token:tokenizer){
filter(token);
}
}
4. Christopher Kohlhoff, N3964 - Library Foundations for Asynchronous Operations, Revision 1 ↩